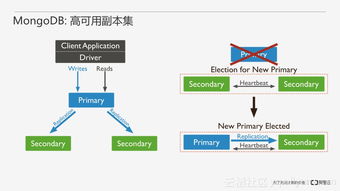
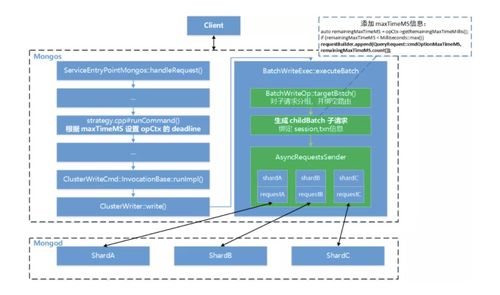
在高并發場景下,尤其像騰訊云這樣承載億級用戶的MongoDB數據庫服務,服務的穩定性至關重要。雪崩效應——即因少數慢查詢或資源占用導致整個數據庫服務的性能急劇下降甚至宕機——是運維中必須防范的風險。maxTimeMS 是MongoDB提供的一項關鍵功能,它不僅保護單個查詢的性能,更能從根源上防止連鎖反應引發的服務雪崩。本文將深入分析如何使用 maxTimeMS 抵御服務雪崩,結合實踐以及騰訊云的過往優化經驗,為讀者提供可落地的解決方案。\n\n## 問題的起源:雪崩效應的隱性風險\n\n在云原生環境中數據庫常成為關鍵瓶頸。以CynosDB(騰訊云自研分布式數據庫)、MongoDB Sharding集群為例,慢請求往往不能主動釋放占用的連接與緩存;若請求集中在某個分片并占滿路代碼特權,可能瞬間消耗節點對應的 disk Cache 堆疊 OPS (磁盤IO操作等),形成長鏈式請求變慢而不斷擴大范圍,相繼崩潰演變成雪崩的先述警告:無法跟蹤—可用備用關閉” \n\n####**1.源頭觸發器:\n先是一部文檔結構導致了范圍 query_owner=\
巧用 maxTimeMS 服務端超時,避免承載億級用戶的騰訊云數據庫 MongoDB 服務雪崩
如若轉載,請注明出處:http://m.ycbdkj.cn/product/77.html
更新時間:2026-05-30 20:49:31